
Митап №1: Презентация Облака УВА Advanced
29.08.2025
Руководителю. Разработчику. Пользователю
Меня зовут Евгений и я приветствую вас от лица Отдела аудита информационных технологий Северо-Западного банка!
Мы пригласили вас для того чтобы познакомить с Облаком УВА Advanced, с тем набором облачных услуг, которые при нашем содействии теперь доступны всем подразделениям Управления внутреннего аудита.
Информация адресована широкому кругу слушателей:
- руководителю, которому важно понять общие подходы и возможности;
- разработчику, который пишет приложения и собирает их в единый сервис;
- пользователю, или подписчику, который пользуется готовыми данными.
От нас
- Инструкция: https://uva-advanced.s3-website.cloud.ru/
- Телеграм-группа: https://t.me/+9LV2MDAGuVtkOGJi
- Евгений Меределин: eimeredelin@sberbank.ru
- Радик Махмутов: rgmakhmutov@sberbank.ru
От вашего отдела (вертикали)
- 2 уполномоченных представителя отдела (администраторы)
Наши цели
Цель, которую мы ставим перед собой, — сделать сбор данных из открытых источников, осуществляемый вами при подготовке к аудиторской проверке, простым и удобным. Таким, каким вы сами захотите его организовать.
Также мы видим миссию своего проекта в накоплении в УВА переиспользуемых решений и лучших практик. Если один отдел добился успехов в обработке какого-то источника данных или в использовании какой-то технологии, то другим целесообразно не идти параллельным курсом, а учиться и переиспользовать опыт, суммировать усилия и по возможности делать свой вклад в развитие компетенций.
- Сбор данных: такой, каким вы сами хотите его сделать.
- Консолидация знаний и лучших практик.
Инфраструктура Облака УВА Advanced
Облако УВА это набор сервисов или услуг, которыми вы можете пользоваться независимо друг от друга. В настоящий момент это: виртуальная машина, сервер PostgreSQL и объектное хранилище — бакеты, аналогичные бакетам S3 от Amazon. Все три сервиса предоставляет Cloud.ru на платформе Advanced. Выбор такого набора услуг для старта Облака УВА продиктован базовой архитектурой любого приложения, которому необходимы доступный 24/7 сервер и хранилище данных.
Исходя из текущего бюджета мы разработали норму оснащения, или “продуктовую корзину” из этих трех сервисов, и каждый профильный отдел (вертикаль) получит настроенные облачные ресурсы в объеме и с параметрами в соответствии с нормой оснащения.
Виртуальная машина: Elastic Cloud Server (ECS)
Подключение — из любого удобного вам терминала или SSH-клиента. У машины открыты несколько популярных портов. Если вашему приложению необходим какой-то специфический порт, мы можем открыть его по вашему требованию.
На машине установлен популярный open-source пакет Fail2Ban. Он блокирует IP-адреса, которые предпринимают подозрительно большое число ошибочных попыток подключения. Это отсекает ботов, которые подбирают пароль к популярным логинам. В Инструкцию добавлен справочник самых востребованных команд.
- конфигурация: 4 vCPUs, 8 GB RAM, Intel Ice Lake 2.6GHz, диск High I/O 60 GB, Ubuntu 24.04, интернет 50 Mbps;
- локальная машина: доступ из любого терминала или SSH-клиента;
- дополнительные учетные записи и делегирование прав — на ваше усмотрение;
- нестандартные порты — по вашему требованию;
- Fail2Ban установлен и настроен.
Сервер PostgreSQL в Relational Database System (RDS)
В сервисе Relational Database System платформы Advanced Cloud.ru мы создали сервер PostgreSQL, версия 17. Общий сервер для всех отделов. Мы заводим для вас учетные записи на сервере, а вы можете создавать любое количество баз данных, схем, таблиц и т.д. Совокупный объем сущностей, созданных сотрудниками отдела, не должен превышать квоту, установленную для отдела. Квота, и вообще вся норма оснащения, для всех отделов единая, привилегий нет. На базы данных postgres в данный момент квота составляет 80 Гб. В будущем, при наличии объективной необходимости, квота может быть увеличена.
Подключение к серверу postgres осуществляется через вашу виртуальную машину. Прямого доступа из интернета, в целях безопасности, нет. Можно подключиться с локальной машины через SSH-туннель — этот способ описан в Инструкции. Можно работать с postgres непосредственно на виртуальной машине: либо установить пакет для Ubuntu, либо запустить контейнер из официального образа в Docker или Podman. Можно работать из графического интерфейса, pgAdmin, а можно из интерфейса командной строки psql. Опций много. Мы не ограничиваем вас в выборе — пожалуйста, используйте то, что вам удобно.
- виртуальная машина как безопасная точка доступа к серверу PostgreSQL
- локальная машина: SSH-туннель к виртуальной машине;
- инструменты:
- pgAdmin (GUI);
- psql (CLI) как компонент дистрибутива PostgreSQL.
- квота на отдел — 80 Гб.
Объектное хранилище: Object Storage Service (OBS)
Предоставление доступа к объектному хранилищу заключается в создании для отдела общего бакета. Совокупный объем объектов, хранимых сотрудниками отдела, не должен превышать квоту, установленную для отдела. Квота на размер бакета единая, в данный момент составляет также 80 Гб, и в случае объективной потребности также может быть увеличена.
Вопрос, который интересует всех. Как собранные в Облаке данные переместить в контур Банка? Решение есть. Подключение к объектному хранилищу через консоль Cloud.ru Advanced выглядит как вход в личный кабинет на сайте. Вы сможете управлять файлами в своем бакете, в том числе скачивать их, прямо из браузера в сигме.
Еще одна приятная опция бакета — подъем на базе него статического сайта. Статический означает, что вся обработка происходит на стороне клиента, т.е. в вашем браузере. Это сайт без бэкенда, который показывает заранее созданные файлы. В данном случае — файлы, лежащие в вашем бакете.
Например, сайт с презентацией, который вы видите на экране, это файл meetup.html, который лежит в бакете uva-advanced, и этот бакет имеет публичный доступ на чтение и настроен как статический сайт. Если создать в бакете структуру вложенных папок, то файлы, лежащие в листовой папке, будут доступны по прямым ссылкам на вашем экране.
Файл того или иного типа будет обработан так, как с этим типом работает ваш браузер. Например, xlsx будет предложено сохранить на диск, а если это аудиофайл, то начнется его потоковое воспроизведение.
В дополнение к основному рабочему бакету вашего отдела, подчеркну — в дополнение, администратор вашего отдела может запросить создание бакета под статический сайт. Права на редактирование контента этого бакета мы настроим по вашему желанию.
Обобщим способы работы с объектным хранилищем:
- в сигме — из браузера через консоль Cloud.ru Advanced, используя логин и пароль.
- с виртуальной машины — используя выданные вам креды программного доступа, через любой интерфейс командной строки для работы с объектными хранилищами: например, AWS CLI, duck, это CLI от Cyberduck, и другие аналоги.
- с локальной машины — всё вышеперечисленное, плюс графические клиенты, например, Cyberduck или рекомендуемый Cloud.ru OBS Browser Plus, работа с которым приводится в Инструкции.
- из-под кода, на виртуальной и локальной машинах, — с помощью python-библиотек boto3, aiobotocore, aioboto3 и др.
- статический сайт из бакета:
- сохранение на диск: …/nested-folder/some-data.xlsx;
- потоковое воспроизведение аудио: …/nested-folder/27-02.mp3.
{kind=link}
- квота на отдел — 80 Гб.
О подходах к наделению правами
Хотим обратить ваше внимание на разницу в подходах к наделению правами между сервером postgres и объектным хранилищем.
На сервере postgres все учетные записи изначально являются равноправными, read-only, и не привязаны к отделам, т.е. нет такого понятия как “командное пространство” и с точки зрения прав каждый сам по себе. Например, вы создали базу данных — значит, вы ее владелец и можете наделять коллег теми или иными дополнительными правами. Симметрично: чтобы получить права сверх чтения на сущность, созданную не вами, вы должны запросить их у владельца. Узнать владельца и отредактировать права можно в свойствах сущности.
В объектном хранилище Облака УВА аналог командного пространства существует — это бакет. Получая доступ к бакету отдела, вы можете писать в него свои объекты и удалять любые объекты ваших коллег по отделу. Но, разумеется, вы не можете изменять содержимое бакетов других отделов — только просматривать и скачивать.
- сервер PostgreSQL: нет командного пространства, владелец наделяет правами на объект;
- объектное хранилище: есть командное пространство — бакет, политика бакета регулирует права на объект.
О разграничении ответственности
О разграничении зон ответственности между администраторами Облака УВА и его пользователями. Мы занимаемся созданием, первичной настройкой, администрированием и передачей ресурсов пользователю в эксплуатацию. При необходимости поможем с подключением. Мы — провайдер услуг. Мы не пишем за пользователя код его приложения. Мы даем удочку, вы — ловите рыбу.
Исключение составляет случай, когда адресат обращения — специалист по конкретному источнику данных или технологии. Обращаться к куратору узкой темы, чтобы переиспользовать накопленные знания или предложить улучшение, — хорошая практика.
Создание ресурсов, первичная настройка, администрирование
Помощь с подключением, устранение ошибок платформы
Не пишем ваш код, не анализируем ошибки, не разбираем логи
Правила пользования Облаком УВА Advanced
Сбор персональных данных с использованием облачных ресурсов УВА запрещен. Этот вопрос регулирует 152-ФЗ. Запрещено собирать данные, которые явным или косвенным образом возможно сопоставить конкретной личности, в том числе запрещено парсить профили в социальных сетях. Перед началом работы с каким бы то ни было информационным ресурсом мы настоятельно просим вас изучить его Пользовательское соглашение. Пожалуйста, изучайте риски и относитесь к этому ответственно, не подставляйте ни себя, ни коллег.
Не храните в базах данных и объектном хранилище информацию, не предназначенную для широкой аудитории. Пользование сервером postgres и бакетами в облаке УВА организовано по принципу
все видят всех и могут выгружать всё
Это принципиальный момент. Облако УВА возможно благодаря тому, что Банк оплачивает его расходы, и потому Облако УВА действует в интересах Банка. А в интересах Банка не просто дать отделу дополнительную рабочую инфраструктуру, а создавать условия для консолидации знаний и лучших практик. Поэтому наш принцип — все видят всех и могут пользоваться всем.
Давайте создаваемым базам данных, таблицам, файлам, папкам и прочим объектам осмысленные имена. В названиях однотипных, пожалуйста, придерживайтесь шаблона или структуры. При создании базы данных заполняйте поле Комментарий. Пожалуйста, думайте об удобстве использования материалов вашими коллегами.
Коллеги, вот сейчас, когда освоение ресурсов еще не началось, есть исторический шанс сделать самим себе удобно и хорошо. Не создавать свалки, как в Супермаркете данных, когда в таблицах нет комментариев и десятки полей с неизвестным смыслом. Здесь и сейчас вы можете сами себе стать инженерами данных.
- Сбор персональных данных с использованием облачных ресурсов УВА запрещен. Перед началом работы, пожалуйста, изучите 152-ФЗ.
- Не отключайте опцию подключения к виртуальной машине с правами root. Нарушение этого правила может привести к блокировке вашей машины.
- Администраторам придерживаться шаблона при создании учетной записи на виртуальной машине:
{имя}-{табельный номер}. Пример: eimeredelin@sberbank.ru →eimeredelin-2042974.
- Не храните в базах данных и объектном хранилище информацию, не предназначенную для широкой аудитории. Пользование сервером PostgreSQL и бакетами в Облаке УВА организовано по принципу🤝
все видят всех и могут выгружать всё
- Давайте сущностям осмысленные имена. В названиях однотипных придерживайтесь шаблона/структуры. При создании базы данных заполняйте поле Комментарий. Пожалуйста, думайте об удобстве использования материалов вашими коллегами.
О совместной работе
Чтобы немного подзадорить вашу творческую энергию, рассмотрим возможную схему работы вашего сервиса в Облаке УВА.
Представьте, что вы — специалист внутри Облака УВА. Один или группа коллег, которые курируют какой-то источник данных или группу источников, объединенных темой. Возможно, вы специалист в какой-то предметной области. Возможно, вы добились успеха в обучении какой-то модели или реализовали какой-то алгоритм и теперь ваш код эффективно вычисляет что-то очень полезное и востребованное внутри УВА. Или пусть вы пока не специалист в теме, но хотите, по зову души или из производственной необходимости, погрузиться в нее и заниматься исследованиями, экспериментировать… Так или иначе, вы — специалист, готовый предоставлять для переиспользования или какие-то регулярно собираемые вами данные, или какой-то кубик знаний, обернутый в код и, например, API.
Вы общаетесь с коллегами, смотрите по пятницам бэклог, просматриваете архивы проверок. Вы понимаете, что ваша компетенция полезна и востребована, и у вас появляется целевая аудитория — потребители ваших данных, ваши внутренние заказчики. Вы проводите среди потребителей исследование и во взаимодействии с ними, как отклик на их заказ, формируете спецификацию поставки данных. Например, если данные табличные, то это состав полей и их типы, требования к форматам и т.д. Если к этому прибавить регламентированную периодичность, то получится подписка на данные. Чтобы реализовать подписку, вы делаете то, что на схеме условно обозначено как Процессор. Это любой код, который по расписанию делает полезную трансформацию ваших сырых данных: очищает, фильтрует по условиям, агрегирует, вычисляет. Это может быть любая модель. А может быть, ваш процессор опрашивает другие API, в том числе другие API внутри Облака УВА, чтобы собранными данными дообогатить свои.
Парсер собирает сырые данные из источника и через API публикует их в базе данных, а API, после коммита, например, автоматически делает копию обновленной базы данных в бакете вашего отдела.
Процессор, когда подходит время, посредством API берет из базы данных сырые данные, трансформирует их, превращая в одну или несколько подписок, и размещает результаты в базе данных. Или в бакете отдела. Или, может быть, в бакете, питающем статический сайт, — в зависимости от спецификации поставки данных. А может быть, вы так условились с заказчиком, что ваш процессор в разные целевые ресурсы постит результаты, полученные с разными параметрами модели… А может быть, ваш заказчик и потребитель данных — это база данных другого отдела, в пайплайне которого данные вашей поставки являются сырыми…
И вот так, из разных сетевых ресурсов Облака УВА, из разных подписок, используя клиент-серверный подход, когда все для всех могут быть одновременно и производителями, и потребителями, мы можем вместе строить сложные цепи обработки и анализа данных.
Эта мысль уже прозвучала выше, но сделаю акцент еще раз. Мы призываем вас не идти разрозненно параллельным курсом, а объединять усилия и переиспользовать их результаты. Например, на старте этого проекта мы проводили среди вас, коллеги, опрос, какие внешние данные вы хотели бы собирать. Отзывы с banki.ru встретились в ответах 4 раза… Вместо того чтобы делать четыре частных разрозненных решения, лучше сделать одно, которое по API будет обслуживать всех. Облако УВА дает нам такую возможность.
- Специалисты внутри Облака УВА.
- Подписки и поставки данных.
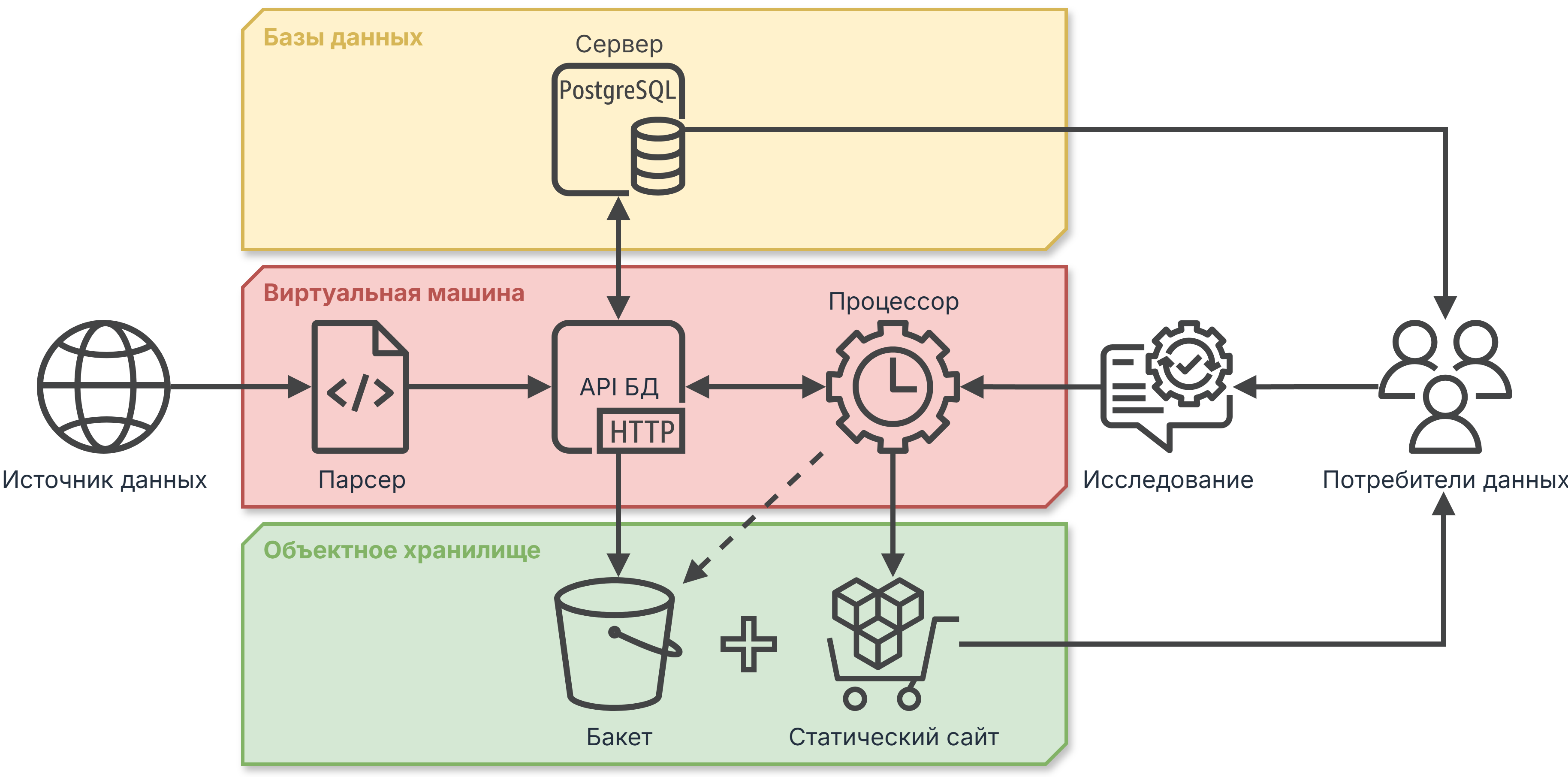
Пример простого сервиса: banki.ru
Упрощенным частным случаем сервиса, изображенного на схеме, который использует все доступные на сегодня услуги Облака УВА, является сервис сбора и хранения негативных отзывов с banki.ru. Он состоит из двух частей: парсера и API базы данных.
Парсер в начале наступившего дня собирает данные за истекшие сутки и отправляет их в API базы данных. API, в свою очередь, публикует пришедшие от парсера новые записи в базе данных на сервере postgres.
Это очень простой пример, здесь нет отдельного “процессора” данных. Его логика зашита в самом API: после каждого коммита (добавления или удаления записей) копия обновленной базы данных в формате parquet перезаписывает предыдущую версию в бакете объектного хранилища.
Таким образом, средствами доставки данных этого сервиса являются сама база данных и бакет ОАИТ, из которого потребитель данных, любой пользователь Облака УВА, согласно контракту поставки может получить что-то вроде кумулятивного релиза — все негативные отзывы пользователей banki.ru с 1 января 2025 г. в компактном формате parquet.
Также API принимает запрос на получение из базы данных выборки, ограниченной датами, в заданном формате. Выборка предоставляется в ответе в виде прямой ссылки на скачивание файла из бакета объектного хранилища. Такой контракт поставки можно сравнить с патчем: потребитель может брать ежедневные приращения в нужном ему формате или данные за произвольный период.
Пошаговую реализацию этого простого проекта, с акцентом на инструменты, которые мы считаем удобными и рекомендуем всем, вы также найдете в Инструкции. Там мы:
- подготовили проект на локальной машине с помощью менеджера uv;
- создали для проекта репозиторий с помощью GitHub CLI;
- склонировали репозиторий на виртуальную машину и запустили API базы данных с помощью юнита systemd;
- пообщались с API с помощью HTTPie CLI и увидели соответствующие изменения в базе данных на сервере postgres и в бакете объектного хранилища.
Кроме того, мы вскользь коснулись платформы Pydantic Logfire для сбора телеметрии и логов приложений, а также перечислили достоинства замечательного SSH-клиента Termius.
- Репозитории: парсер и API базы данных.
- Пошаговая реализация в Облаке УВА Advanced.
- Инструменты: uv, GitHub CLI, systemd, HTTPie CLI, Pydantic Logfire, Termius.
Мы открыты для обратной связи
Коллеги, наш сервис находится только в самом начале своего пути. Наверняка еще многое будет меняться. В том числе услуги, наполняющие Облако УВА. Если у вас есть потребность в облачных сервисах, не входящих сейчас в меню Облака УВА, пожалуйста, пишите нам. Мы открыты для обратной связи. Конечно, мы не можем обещать быстрого исполнения ваших пожеланий, но информация, безусловно, будет изучаться и приниматься к сведению при составлении плана развития Облака УВА.
Что касается оперативной связи по работе действующих сервисов, вы можете писать в телеграм-группе Облака УВА.
